- 1 за тачно или
- 0 за фалсе
Кључни значај логистичке регресије:
- Независне променљиве не смеју бити мултиколинеарност; ако постоји нека веза, онда би то требало бити врло мало.
- Скуп података за логистичку регресију треба да буде довољно велик да би се постигли бољи резултати.
- Само би ти атрибути требали бити тамо у скупу података, што има неко значење.
- Независне променљиве морају бити у складу са лог квоте.
Да би се изградио модел логистичка регресија, користимо сцикит-научити библиотека. Процес логистичке регресије у питхону је дат у наставку:
- Увезите све потребне пакете за логистичку регресију и друге библиотеке.
- Отпремите скуп података.
- Разумевање независних променљивих скупа података и зависних променљивих.
- Поделите скуп података на податке о обуци и тестирању.
- Иницирајте модел логистичке регресије.
- Модел прилагодите скупу података о обуци.
- Предвидите модел помоћу података теста и израчунајте тачност модела.
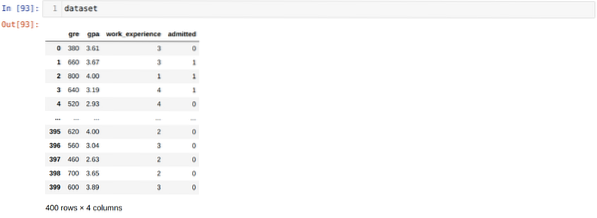
Проблем: Први кораци су прикупљање скупа података на који желимо да применимо Логистичка регресија. Скуп података који ћемо овде користити служи за скуп података за пријем у МС. Овај скуп података садржи четири променљиве, а од тога су три независне променљиве (ГРЕ, ГПА, ворк_екпериенце), а једна је зависна променљива (примљена). Овај скуп података ће рећи да ли ће кандидат добити пријем на престижни универзитет на основу свог ГПА, ГРЕ или радног искуства.
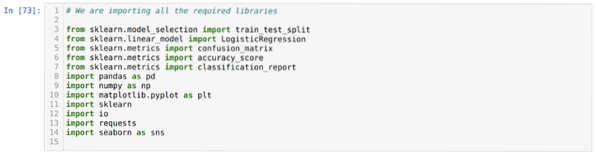
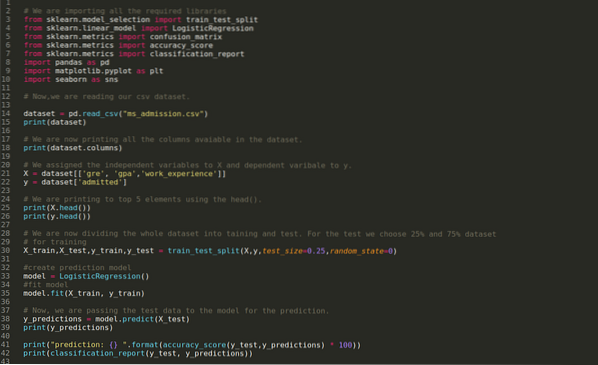
Корак 1: Увозимо све потребне библиотеке које смо захтевали за програм питхон.
Корак 2: Сада учитавамо свој скуп података за пријем мс помоћу функције панди реад_цсв.

Корак 3: Скуп података изгледа испод:
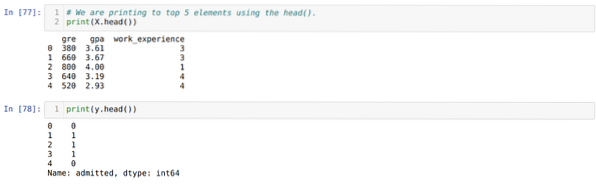
Корак 4: Проверавамо све колоне доступне у скупу података, а затим постављамо све независне променљиве на променљиву Кс, а зависне променљиве на и, као што је приказано на слици испод.

Корак 5: Након што смо независне променљиве поставили на Кс, а зависне променљиве на и, овде сада штампамо да бисмо проверили Кс и и помоћу функције хеад пандас.
Корак 6: Сада ћемо поделити читав скуп података на тренинг и тест. За ово користимо методу траин_тест_сплит склеарна. За тест смо дали 25% целокупног скупа података, а за обуку преосталих 75% скупа података.
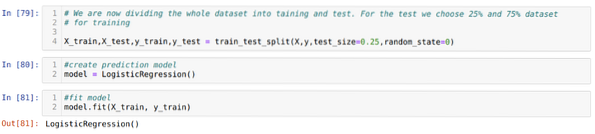
Корак 7: Сада ћемо поделити читав скуп података на тренинг и тест. За ово користимо методу траин_тест_сплит склеарна. За тест смо дали 25% целокупног скупа података, а за обуку преосталих 75% скупа података.
Затим креирамо модел логистичке регресије и прилагођавамо податке о обуци.
Корак 8: Сада је наш модел спреман за предвиђање, тако да сада преносимо тест (Кс_тест) податке моделу и добили смо резултате. Резултати показују (и_предицтионс) да вредности 1 (прихваћене) и 0 (неприхваћене).

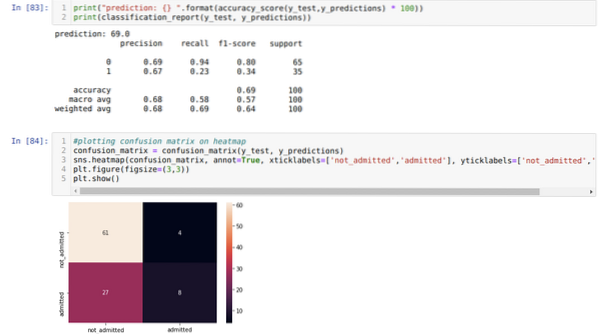
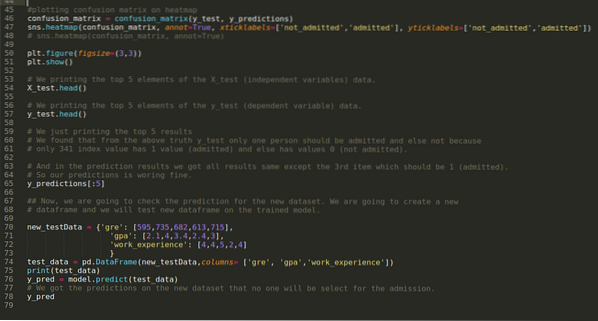
Корак 9: Сада исписујемо извештај о класификацији и матрицу забуне.
Извештај о класификацији показује да модел може предвидети резултате са тачношћу од 69%.
Матрица забуне приказује укупне детаље Кс_тест података као:
ТП = истински позитивни = 8
ТН = Прави негативи = 61
ФП = лажно позитивни = 4
ФН = Лажни негативци = 27
Дакле, укупна тачност према цонфусион_матрик је:
Тачност = (ТП + ТН) / Укупно = (8 + 61) / 100 = 0.69
Корак 10: Сада ћемо унакрсно провјерити резултат кроз штампу. Дакле, само исписујемо 5 најбољих елемената Кс_тест и и_тест (стварна стварна вредност) помоћу функције хеад пандас. Затим, такође исписујемо 5 најбољих резултата предвиђања као што је приказано доле:
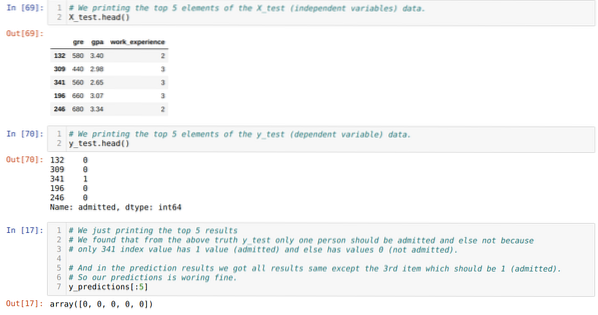
Комбинујемо сва три резултата у листу да бисмо разумели предвиђања као што је приказано у наставку. Можемо видети да је осим података о 341 Кс_тест, који су били тачни (1), предвиђање нетачно (0). Дакле, наша предвиђања модела раде 69%, као што смо већ показали горе.

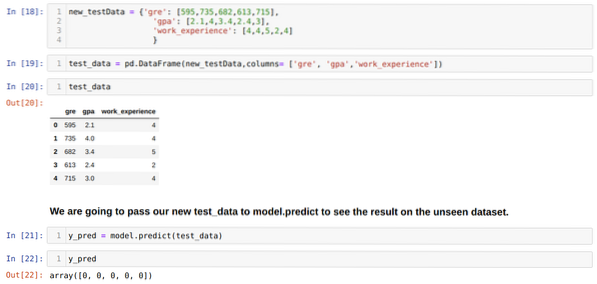
Корак 11: Дакле, разумемо како се предвиђања модела раде на невиђеном скупу података попут Кс_тест. Дакле, креирали смо само насумично нови скуп података користећи оквир података пандас, проследили га обученом моделу и добили резултат приказан испод.
Комплетни код у питхон-у дат у наставку:
Код овог блога, заједно са скупом података, доступан је на следећој вези
хттпс: // гитхуб.цом / схекхарпандеи89 / логистиц-регрессион


